PyTorchのMultiGPUの概要 【DataParallel, DistributedDataParallel, torchrun】
DataParallel と DistributedDataParallel
PyTorch で複数の GPU を用いた Training の実装方法は 2 つある。
torch.nn.DataParalleltorch.nn.DistributedDataParallel
この2つの違いは、複数の GPU に割り当てられるCPUコアが 全体で1つか各GPUに複数かである。
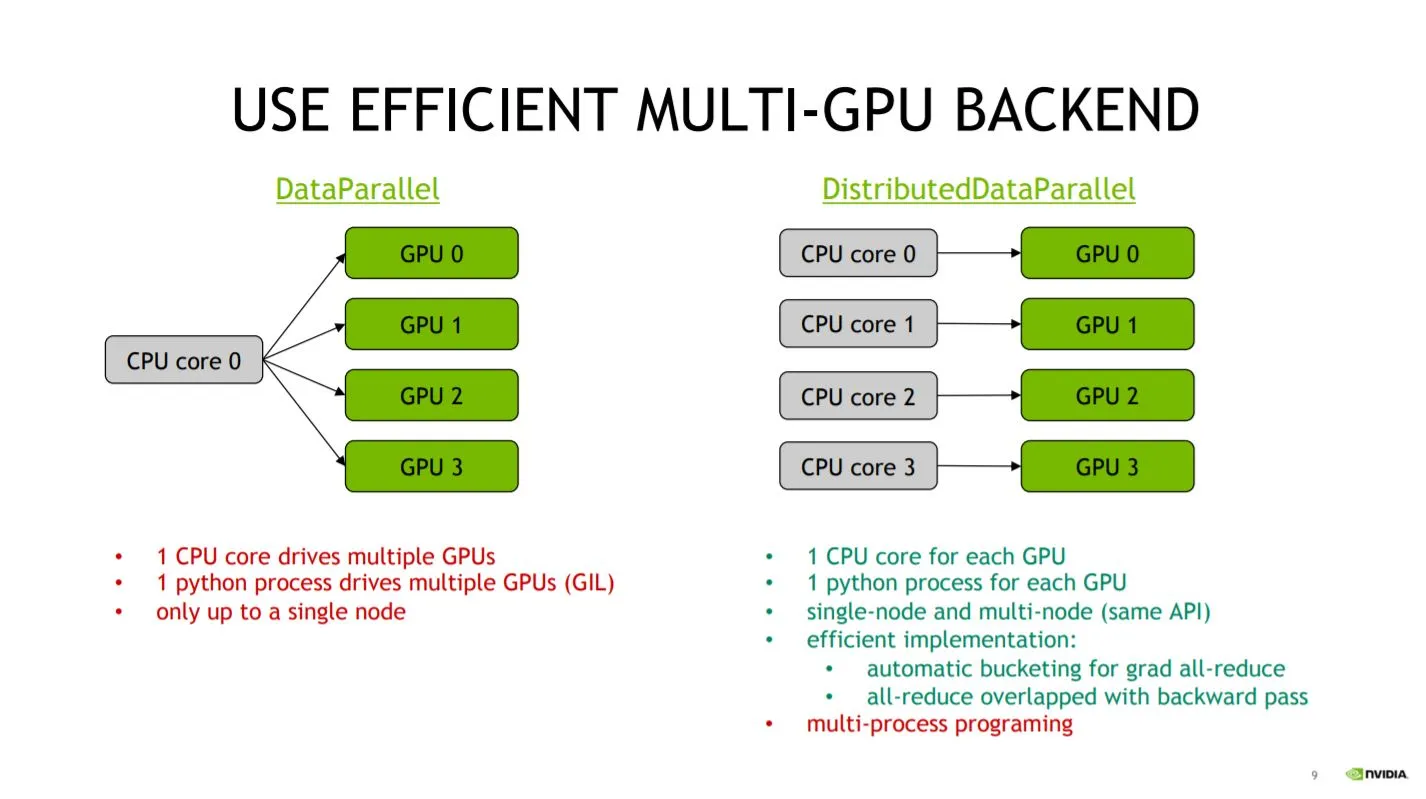
上記の図1のように、Python の GIL の都合もあり、
DistributedDataParallelを使ったほうが各 GPU に個別の CPU コアを割り当てられるので、
リソースを存分に使うことができる。
また、複数のマシン(Multi-node)で実行できるのも強みである。
実際、公式ドキュメント2でもDistributedDataParallelが勧められている。
ここまでくると、DataParallelのメリットが感じられないが、実装の違いを
見ると利点が見えてくる。
まず、DataParallelの実装は以下である。
import torch
model = hoge()
+ model = torch.nn.DataParallel(model, device_ids=[0,1,2,3])上記のように既存のモデル(torch.nn.Model)に対して、torch.nn.DataParallelをラップするだけで
実装でき、既存のコードを 1 行変更するだけで実装することができる。
次に、DistributedDataParallelの実装例を確認する。
import os
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data.distributed import DistributedSampler
# どのGPUプロセス番号かがLocal Rank
# GPU ID = 1の時、local_rank=1
local_rank = os.getenv('LOCAL_RANK', 0)
# 通信方法の規定とプロセスグループの初期化
dist.init_process_group(backend='nccl', init_method='env://')
dataset = Dataset(hoge)
# DistributedSamplerを使う
sampler = DistributedSampler(dataset, rank=local_rank)
dataloaders = torch.utils.data.DataLoader(dataset,
batch_size=16,
sampler=Distributed)
# DistributedDataParallelでラップ
model = Model(fuga)
model = DDP(model)
# ...
# Training終了
dist.destroy_process_group()DistributedDataParallelでは、シングル・マルチマシンの場合も同じ書き方ができるように
設計されているため、新たに実装する部分が多い。
マルチプロセスになった分、自分が今どのプロセスにいるのかを意識しながら実装を進める必要がある。
上記の通り、DataParallelは 1 行で既存のコードを変更することができるが、
DistributedDataParallelは多少の追加実装が必要になる。
手軽に複数 GPU での Training を試したい場合は、DataParallelを用いるとよい。
次章では新たに追加されたtorchrunについて議論するため、以下からはDistributedDataParallel
を用いた場合について考える。
DistributedDataParallel の実行方法
DistributedDataParallel の実行方法は、大きく分けて以下の2つある。
- 特定の関数について GPU 並列化を行う方法(
mp.spawn) - スクリプトごと GPU 並列化する方法(
torchrun,torch.distributed.run,torch.distributed.launch)
1. 関数について並列化
1 の関数ごとに並列化する方法は、コード内で Training を行う関数を書いて、使用する GPU の数や
通信方法もコード内で設定して実行することができる。
つまり、シングル GPU であっても、複数 GPU のコードであってもpython train.pyと、
同じコマンドの実行で学習が行える。
実装例は PyTorch 公式の ImageNet 学習の実装に書かれている。
2 の方法と大きく異なる部分が、以下の部分である。
import torch.multiprocessing as mp
def train(rank, hoge):
dist.init_process_group(backend='nccl', init_method='env://')
def main():
mp.spawn(train, nprocs=ngpus_per_node, args=(hoge))上記の通り、コード自体は Python 標準モジュールの multiprocessing と変わりない。
しかし、標準モジュールは CUDA Initialized を複数行ってしまい、エラーが発生するため、
multiprocessing モジュールをラップした、torch.multiprocessingを使用する。
2. スクリプトごと並列化
2 の方法については PyTorch のバージョンによって実行方法が異なっており、
version 1.9.0 以前は、
python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 --node_rank 0 train.py
で実行されていたが、version 1.9.0 以降は TorchElastic が追加された影響で
python -m torch.distributed.run --nproc_per_node=4 --nnodes=1 --node_rank 0 train.py
でも実行できる。
また、torch.distributed.launchの super set として、torchrunが Version 1.10.0 から提供されている。
ここでは従来の方法である、torch.distributed.launchとtorch.distributed.runについて述べる。
torch.distributed.launchとtorch.distributed.runの場合、
実行スクリプトのtrain.pyにはコマンドライン引数として
--local_rankを受け取れるように実装する必要がある。下に例を示す。
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int)
args = parser.parse_args()
local_rank = args.local_rankこれ以外の実装は 1 の関数ごとに multiprocessing する場合と変わらない。
1 と 2 の実行方法の違いについて
1 の関数を multiprocessing する方法と、スクリプト自体を multiprocessing する方法は、
こちらの公式フォーラム
3でも言及されているように、
multiprocessing(1) vs subprocess(2)の違いといえる。
Github の Issue4 5では、1 の方法が GPU への転送速度の関係で遅いという報告もある。 長い時間の学習では無視できるようだが、参考としておきたい。
新しい実行方法 torchrun
PyTorch の Version 1.10.0 から、torch.distributed.launchの super set として、torchrunが登場している。
公式ドキュメント6にわかりやすい移行手順があるので、一読をお勧めする。
具体的には、実行コマンドが以下のように変更され、
# use_envはLOCAL RANKをargparseではなく、
# 環境変数から受け取るオプション
python -m torch.distributed.launch --use_env train_script.py
torchrun train_script.pyargparse で受け取っていた local rank を環境変数から受け取るようになる。
# torch.distributed.launch
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int)
args = parser.parse_args()
local_rank = args.local_rank
# torchrun
import os
local_rank = int(os.environ["LOCAL_RANK"])ほとんど使用感は変わりないが、わざわざ argparse で引数の受取先を作らなくてよくなったのは、
コマンドライン引数の名前空間を汚されなくて済むので利点がある。
例えば、Facebook 謹製の設定管理ライブラリの
Hydra 7を使っている場合、argparse と併用ができないので、
torchrun で環境変数を経由するメリットがある。
(ただし、ここ8 9で議論されているように、output 周りが conflict する問題があるので、
今後の動向に注目するべきである。)
ここ10で、書かれているようにtorch.distributed.launch
は将来的に deprecated したいようなので、今後は torchrun で実装していくべきだろう。
参考
Footnotes
-
https://qiita.com/sugulu_Ogawa_ISID/items/62f5f7adee083d96a587#4-multi-gpu%E3%81%AE%E8%A8%AD%E5%AE%9A ↩
-
https://pytorch.org/docs/1.11/notes/cuda.html#use-nn-parallel-distributeddataparallel-instead-of-multiprocessing-or-nn-dataparallel ↩
-
https://discuss.pytorch.org/t/torch-distributed-launch-vs-torch-multiprocessing-spawn/95738 ↩
-
https://pytorch.org/docs/1.11/distributed.html#launch-utility ↩